TensorFlow e sua composição

Em Novembro de 2015 foi lançado uma das mais incríveis bibliotecas de Machine Learning, o Google TensorFlow. Atualmente o crescimento desta biblioteca tem crescido de uma forma imensurável, com constantes atualizações, novas features e uma comunidade muito ativa.
Muito se fala em TensorFlow atualmente, mas afinal o que é o TensorFlow? Ao longo deste artigo iremos explicar o que é este importante framework, mas tambem mostrar os dois principais fatores do surgimento desta biblioteca, o fenômeno BIg Data e Deep Learning.
Conhecendo Big Data
Vivemos numa era de total explosão de informação, onde dados estão sendo gerado de todos os lugares, por qualquer dispositivo, em volume gigantesco e uma velocidade estonteante, através de Smartphones, relógios, Tvs, sensores, eletrodomésticos, etc.. A grande maioria destes dispositivos já estão sendo gerados para armazenar dados na nuvem, pois a capacidade de armazenamento em nuvem é um fator quase ilimitado. O resultado desse armazenamento são Petabytes de dados sendo gerados por dispositivos e seus respetivos usuários a uma velocidade gigantesca.Desafiando a Lei de Moore,a capacidade computacional está crescendo de uma forma desenfreada, não na capacidade de processamento das CPUs mas com o crescimento de uma arquitetura de processamento paralela usando as GPUs (Unidades de Processamento Gráfico), que tinham como objetivo inicial para jogos de computador, estão agora sendo utilizadas para computação geral, possibilitando processamento em alta velocidade e por sua vez melhorando a capacidade de processamento no aprendizado de máquina, reduzindo o seu tempo de processamento e capacitando um processamento de grandes volumes de modelos cada vez mais eficientes.
O Machine Learning usa em sua grande parte, modelos matemáticos e estatísticos para poder responder a questões utilizando dados. Quantos mais dados e quanto maior a capacidade de processamento em grande escala, mais perguntas podem ser respondidas de forma precisa e eficaz.
É esse o fenômeno Big Data, não é uma tecnologia, não é um framework ou ferramenta, é um fenômeno, o surgimento de dados, principalmente dados não estruturados em grande escala, veracidade e velocidade, fizeram surgir aquilo que hoje chamamos de Big Data.
Conhecendo Deep Learning
Deep Learnig é um termo usado para o uso de redes neurais de múltiplas camadas e que podem ser usadas para uma incrível variedade de diferentes combinações de técnicas matemáticas. Existe um poder incrível nesses modelos, porém a habilidade do uso das mesmas de forma eficiente é algo recente, contudo devido á massiva quantidade de dados disponíveis (Big Data) e a elevada capacidade computacional (GPUs), os modelos de Deep Learnig começam as ser uma técnica extremamente utilizada e muito poderosa.
Algo que diferencia o modelo de Deep Learnig dos demais de IA, é a flexibilidade em decidir como os dados serão usado para gerar o melhor resultado possível.
Com esta técnica, o fator humano do Cientista de Dados de ficar decidindo quais os inputs devem ser incluídos, fica bastante reduzido, uma vez que modelos de Deep Learnig podem considerar todos os parâmetros e de forma automática escolher a melhor combinação dos valores de entrada. Com esse fator a nosso favor, o processo de tomada de decisão consegue atingir um nível de acurácia altamente sofisticada e precisa, possibilitando a conversão de máquinas e dispositivos, mais inteligentes que nunca.
Ainda que os conceitos matemáticos por trás do Deep Learning existam há muitas décadas, as bibliotecas exclusivas para treinar modelos de Deep Learning, surgiram recentemente, mostrando que ainda existe um universo muito grande para explorar. O grande problema está no dilema que essas bibliotecas possuem, no que concerne flexibilidade e a sua possibilidade de uso em produção. Ter bibliotecas flexíveis ao nosso dispor é excelente para pesquisa e desenvolvimento de novas arquiteturas, porém as mesmas não estão totalmente aptas para o uso em produção com aplicações críticas de sistemas web por exemplo.
Ainda assim existem bibliotecas velozes e bastante eficientes para execução em ambientes paralelos e distribuídos, o que as tornam excelente alternativas para produção, porém especializadas em um numero limitado de redes neurais que por sua vez possuem pouca flexibilidade. Certamente que com isto, um grande dilema surge, no que diz respeito á escolha de qual biblioteca escolher, e é exatamente aí que o TensorFlow se apresenta como uma possível solução.
Google TensorFlow
O TensorFlow, teve sua versão open-source liberada em Novembro de 2015, resultado de anos de aprendizado com seu antecessor, o DistBielief.
Criado para ser flexível, eficiente, extensível e portável, pode ser executado em um computador de qualquer natureza, desde smartphones a clusters de computadores.
Como principal características, o TensorFlow, consegue de forma rápida, gerar um produto ou serviços a partir de um modelo preditivo treinado, eliminando a necessidade de reimplementar o modelo.
É sem duvida uma biblioteca muito inovadora, contando com uma comunidade muito ativa, podendo ser utilizado para pequisas ou implementações de estratégias de Inteligencia Artificial, tal como a Google utiliza.
Inicialmente a Google utilizada o DistBelief para o uso de Deep Learnig em larga escala, criado pela equipe Google Brain, tem sido muito utilizado por dezenos de equipes para projetos que envolvem redes neurais profundas.
No entanto, como ocorre com muitos projetos de engenharia de primeira classe, houve erros de projeto que limitaram a usabilidade e a flexibilidade do DistBelief. Algum tempo após a criação do DistBelief, o Google começou a trabalhar no seu sucessor, cujo design aplicaria lições aprendidas com o uso e as limitações do DistBelief original. Este projeto transformou-se no TensorFlow, que rapidamente se tornou uma biblioteca popular para o aprendizado da máquina e está sendo usado atualmente para o processamento de linguagem natural, inteligência artificial, visão computacional e análise preditiva.
No proprio site do TensorFlow, temos uma descrição alternativa so que realmente é o TensorFlow:
é uma biblioteca de software de código aberto para computação numérica usando gráficos de fluxos de dados.
TensorFlow foi originalmente criado pelo Google como uma ferramenta de aprendizagem de máquina, mas uma implementação do mesmo foi liberada sob a licença Apache 2.0 em novembro de 2015. Como software de código aberto, qualquer pessoa tem permissão para baixar, modificar e usar o código. Devido à popularidade que TensorFlow ganhou, há melhorias feitas na biblioteca diariamente – criadas por desenvolvedores do Google e de terceiros.
Tecnicamente falando, TensorFlow é uma interface para computação numérica como descrito no white paper TensorFlow e o Google ainda mantém sua própria implementação interna do software. No entanto, as diferenças entre a implementação de código aberto e implementação interna do Google são devido a conexões com outros softwares internos. O Google está constantemente gerando aprimoramentos e disponibilizando no repositório público no Github e, para todos os efeitos, o release de código aberto contém as mesmas capacidades que a versão interna do Google.
O TensorFlow é projetado para ser escalável em vários computadores, bem como várias CPUs e GPUs dentro de máquinas individuais. Embora a implementação de código aberto original não tivesse recursos distribuídos após a liberação, a partir da versão 0.8.0 a funcionalidade de execução distribuído ficou disponível como parte da biblioteca interna TensorFlow. Embora esta API distribuída seja um pouco pesada, é incrivelmente poderosa. A maioria das outras bibliotecas de aprendizagem de máquinas não possui esses recursos e é importante observar que a compatibilidade nativa com determinados gerenciadores de cluster está sendo trabalhada.
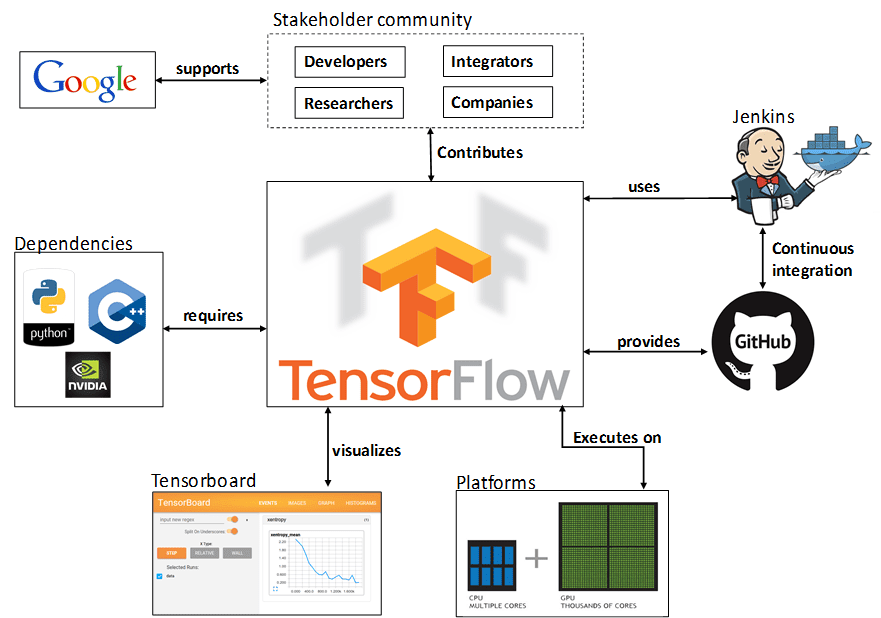
TensorFlow é a API para definir modelos de aprendizado de máquina, treiná-los com dados e exportá-los para uso posterior. A API primária é acessada através do Python, enquanto a computação real é escrita em C++. Isso permite que os cientistas e engenheiros de dados utilizem um ambiente mais “user-friendly” em Python, enquanto a computação real é feita com código C++ rápido e compilado. Existe uma API C++ para executar modelos TensorFlow, mas ainda é limitada e não é recomendada para a maioria dos usuários.
O TensorBoard é um software de visualização de gráficos que está incluído em qualquer instalação TensorFlow padrão. Quando um usuário inclui certas operações específicas de TensorBoard em TensorFlow, TensorBoard é capaz de ler os arquivos exportados por um gráfico TensorFlow e pode dar uma visão sobre o comportamento de um modelo. É útil para estatísticas de resumo, analisar o treinamento e depurar seu código TensorFlow. Aprender a usar TensorBoard desde cedo, permitirá trabalhar com TensorFlow de forma mais agradável e produtiva.
O TensorFlow Serving é um software que facilita a instalação de modelos TensorFlow pré-treinados. Usando funções TensorFlow embutidas, um usuário pode exportar seu modelo para um arquivo que pode então ser lido nativamente pelo TensorFlow Serving. É então capaz de iniciar um servidor simples de alto desempenho que pode receber dados de entrada, passá-los para o modelo treinado e retornar a saída do modelo. Além disso, o TensorFlow Serving é capaz de alternar de modo contínuo modelos antigos com novos, sem qualquer tempo de inatividade para os usuários finais. Embora o TensorFlow Serving seja possivelmente a porção menos reconhecida do ecossistema TensorFlow, pode ser o que o diferencia da sua concorrência. Incorporar o Serving em um ambiente de produção permite que os usuários evitem reimplementar seu modelo. TensorFlow Serving é escrito inteiramente em C++ e sua API só é acessível através de C++.
Quando usar:
- Pesquisa e desenvolvimento e iteração atravé de novas arquitetruas de machine learning
- Implementação de modelos diretamente em produção.
- Implementação de arquiteturas complexas e existentes
- Modelos Distribuídos de Larga Escala
- Treinamento e criação de modelos para sistemas móveis e/ou embarcados.
O TensorFlow pode ser usado em Linux,MacOS, Windows e Docker.
Referências:



Comentários
Postar um comentário