Tutorial de Deep Learning com Keras
Tutorial de Deep Learning com Keras
O Objetivo deste artigo é dar uma introdução do que é Deep Learning e alguns exemplo de seu uso.
Irei explicando passo a passo de cada execução, com base num estudo que fiz no Kaggle.
No final deste tutorial, você terá informações suficientes sobre Deep Learing para poder futuramente aprofundar seu conhecimento.
Partes do código são escritas em inglês devido á universalidade da linguagem de programação
Partes do código são escritas em inglês devido á universalidade da linguagem de programação
Vamos analisar o conteúdo.
Conteúdo:
- Introdução
- Visão geral do conjunto de dados
- Regressão logística
- Gráfico de computação
- Inicializando Parâmetros
- Propagação direta
- Função Sigmoide
- Função de perda (erro)
- Função de custo
- Algoritmo de otimização com descida de gradiente
- Propagação para trás ( retro-propagação)
- Atualizando parâmetros
- Regressão logística com Sklearn
- Resumo e Perguntas em Mente
- Artificial Neural Network
- Rede Neural de 2 Camadas
- Tamanho das camadas e pesos dos parâmetros de inicialização e viés (Bias)
- Propagação direta
- Função de perda e função de custo
- Propagação para trás ( retro-propagação)
- Atualizando parâmetros
- Previsão com parâmetros aprendidos peso e viés (Bias)
- Criação do Modelo
- Rede neural de camada L
- Implementando com a Biblioteca Keras
- Conclusão
- Referências
Introdução
- Deep Learning: Uma das técnicas de aprendizado de máquina que aprende recursos diretamente dos dados.

- Porquê Deep Learning?: Quando a quantidade de dados aumenta, as técnicas de aprendizado de máquina são insuficientes em termos de desempenho, e o Deep Learning oferece melhor desempenho, como precisão.
- O que é grande volume de dados?: É difícil responder, mas intuitivamente 1 milhão de amostras é suficiente para dizer "grande quantidade de dados"
- Campos de uso do Deep Learning: Sistemas de reconhecimento de voz, classificação de imagem, processamento em linguagem natural (PNL) ou recomendação de sistemas
- Qual a diferença entre Deep Learing e Machine Learning?:
- O Machine Learning abrange o Deep Learining
- Os recursos recebem Machine Learning manualmente.
- Por outro lado, o Deep Learning aprende recursos diretamente dos dados.

Vamos dar uma olhadas nos dados


- Para criar uma matriz de imagens, concatenei os sinais zero e um em um array de sinais.
- Em seguida, crio a matriz de etiquetas 0 para zero imagens de sinal e 1 para imagens de um sinal.

- A forma do X é (410, 64, 64
- 410 significa que temos 410 imagens (zero e um sinal)
- 64 significa que o tamanho da nossa imagem é 64x64 (64x64 pixels)
- A forma do Y é (410,1)
- 410 significa que temos 410 rótulos (0 e 1)
- Vamos dividir X e Y em conjuntos de treino e teste.
- test_size = porcentagem do tamanho do teste. teste = 15% e trem = 75%
- random_state = use a mesma semente durante a randomização. Isso significa que, se chamarmos train_test_split repetidamente, ele sempre criará a mesma distribuição de treino e teste porque temos o mesmo estado aleatório.

- Agora, como temos um array de entrada tridimensional (X), precisamos nivelá-lo (2D) para usá-lo como entrada para o nosso primeiro modelo de Deep Learning.
- Nossa matriz de etiquetas (Y) já está nivelada (2D), portanto, deixamos assim.
- Permite achatar a matriz X (matriz de imagens).

- Como você pode ver, temos 348 imagens e cada imagem possui 4096 pixels na matriz de treino de imagens.
- Além disso, temos 62 imagens e cada imagem possui 4096 pixels na matriz de teste de imagens.
- Então vamos fazer a transposição. Você pode dizer que POR QUE, na verdade, não há resposta técnica. Acabei de escrever o código (código que você verá nas próximas partes) de acordo com ele

O que fizemos até agora:
- A escolha de nossos rótulos (classes) que correspondem zero e a um
- Criar e nivelar conjuntos de treino e teste
- Nossas entradas finais (imagens) e saídas (etiquetas ou classes) são assim:

Regressão Logística
- Quando falamos de classificação binária (saídas 0 e 1), o que vem à mente primeiro é a regressão logística.
- No entanto, no tutorial de Deep Learning, o que fazer com a regressão logística?
- A resposta é que a regressão logística é na verdade uma rede neural muito simples.
- A propósito, rede neural e Deep Learning são a mesma coisa. Quando chegarmos à rede neural artificial, explicarei detalhadamente os termos como "Deep".
- Para entender a regressão logística (Deep Learing simples), primeiro aprenda o gráfico de computação.
Gráfico de Computação
- Os gráficos de computação são uma boa maneira de pensar em expressões matemáticas.
- É como a visualização de expressões matemáticas.
- É gráfico computacional é isso. Como você pode ver, expressamos matemática com gráfico.

Agora vamos ver o gráfico de computação da regressão logística:

- Os parâmetros são peso e viés (bias).
- Pesos: coeficientes de cada pixel
- viés (bias): interceptar
- z = (w.t) x + b => z é igual a (transposição dos pesos vezes a entrada x) + polarização
- Em outra visão => z = b + px1w1 + px2w2 + ... + px4096 * w4096
- y_head = sigmóide (z)
- A função sigmóide faz z entre zero e um, de modo que é probabilidade. Você pode ver a função sigmóide no gráfico de computação.
- Por que usamos a função sigmóide?
- Dá resultado probabilístico
- É derivativo para que possamos usá-lo no algoritmo de descida de gradiente (veremos em breve).
- Vamos dar um exemplo:
- Digamos que encontramos z = 4 e colocamos z na função sigmóide. O resultado (y_head) é quase 0,9. Isso significa que nosso resultado de classificação é 1 com 90% de probabilidade.
- Agora vamos começar do início e examinar cada componente do gráfico de computação mais detalhadamente.
Inicialização de Parâmetros
- Como você sabe, a entrada são nossas imagens com 4096 pixels (cada imagem em x_train).
- Cada pixel tem pesos próprios.
- O primeiro passo é multiplicar cada pixel com seu próprio peso.
- A questão é: qual é o valor inicial dos pesos?
- Existem algumas técnicas que explicarei na rede neural artificial, mas, para esse período, os pesos iniciais são 0,01.
- Ok, os pesos são 0,01, mas qual é a forma da matriz de pesos? Como você entende pelo gráfico computacional da regressão logística, é (4096,1)
- O viés (bias) inicial também é 0.
- Vamos escrever algum código. Para usar nos próximos tópicos como rede neural artificial (RNA), eu faço a definição (método).


Propagação Direta
- Todas as etapas, de pixels a custo, são chamadas propagação direta
- z = (w.T) x + b => nesta equação, sabemos x que é uma matriz de pixels, sabemos w (pesos) e (viés), de modo que o resto é cálculo. (T é transposição)
- Em seguida, colocamos z na função sigmoide que retorna y_head (probabilidade). Quando sua mente estiver confusa, veja o gráfico de computação. Também a equação da função sigmoide está no gráfico de computação.
- Então calculamos a função de perda (erro) - loss(error).
- A função de custo é a soma de todas as perdas (erro).
- Vamos começar com z e a definição sigmoide de gravação (método) que usa z como parâmetro de entrada e retorna y_head (probabilidade)

- Enquanto escrevemos o método sigmoide e calculamos y_head. Vamos aprender o que é a função de perda (erro)
- Vamos dar um exemplo, eu coloquei uma imagem como entrada e multipliquei com seus pesos e adicionei termo de viés para encontrar z. Em seguida, coloquei z no método sigmóide para encontrar y_head. Até este ponto, sabemos o que fizemos. Então, por exemplo, y_head se tornou 0,9 maior que 0,5, então nossa previsão é que a imagem é vinculada a uma imagem. Okey, tudo parece bem. Mas, nossa previsão está correta e como verificamos se está correta ou não? A resposta está na função de perda (erro):
- Diz que, se você fizer uma previsão errada, a perda (erro) se tornará grande. DENKLEM DUZELTME
- Exemplo: nossa imagem real é o sinal 1 e seu rótulo é 1 (y = 1), e fazemos a previsão y_head = 1. Quando colocamos y e y_head na equação de perda (erro), o resultado é 0. Fazemos a previsão correta, portanto, nossa a perda é 0. No entanto, se fizermos previsões erradas como y_head = 0, a perda (erro) será infinito.
- Depois disso, a função de custo é a soma da função de perda. Cada imagem cria uma função de perda. A função de custo é a soma das funções de perda criadas por cada imagem de entrada.
- Permite implementar a propagação direta.

Otimização de Algoritmos com Descida Gradiente
- Bem, agora sabemos qual é o nosso custo que é erro.
- Portanto, precisamos diminuir o custo, porque, como sabemos se o custo é alto, isso significa que fazemos previsões erradas.
- Vamos pensar no primeiro passo, tudo começa com a inicialização de pesos e viés (bias). Portanto, o custo depende deles.
- Para diminuir os custos, precisamos atualizar pesos e viés (bias).
- Vamos dar um exemplo:
- Temos w = 5 e viés = 0 (então ignore o viés por enquanto). Então fazemos propagação para frente e nossa função de custo é 1,5.
- Se parece com isso. (linhas vermelhas)

- Como você pode ver no gráfico, não estamos no ponto mínimo da função de custo. Portanto, precisamos passar pelo custo mínimo. Ok, vamos atualizar o peso. (o símbolo: = está sendo atualizado)
- w: = w - step. A questão é: qual é esse passo? O passo é slope1. Okey, parece notável. Para encontrar o ponto mínimo, podemos usar a slope1. Então digamos slope1 = 3 e atualize nosso peso. w: = w - slope1 => w = 2.
- Agora, nosso peso w é 2. Como você se lembra, precisamos encontrar a função de custo com propagação direta novamente.
- Digamos que, de acordo com a propagação direta com w = 2, a função de custo seja 0,4. Estamos no caminho certo, porque nossa função de custo é decrescente. Temos um novo valor para a função de custo que é custo = 0,4. Isso é suficiente? Na verdade eu não sei, vamos tentar mais um passo.
- Slope2 = 0,7 ew = 2. Permite atualizar o peso w: = w - passo (slope2) => w = 1.3 que é novo peso. Então, vamos encontrar um novo custo.
- Faça mais uma propagação para a frente com w = 1,3 e nosso custo = 0,3. Okey, nosso custo até diminuiu, parece bom, mas é suficiente ou precisamos dar mais um passo? A resposta é novamente eu não sei, vamos tentar.
- Slope3 = 0,01 ew = 1,3. Atualizando peso w: = w - passo (slope3) => w = 1,29 ~ 1,3. Portanto, o peso não muda porque encontramos a função mínima do ponto de custo.
- Tudo parece bom, mas como encontramos a inclinação? Se você se lembra do ensino médio ou da universidade, para encontrar uma inclinação da função (função de custo) em um determinado ponto (com um peso determinado), obtemos derivada da função em um determinado ponto. Mas como ela sabe para onde vai. Você pode dizer que pode aumentar os valores de custo mais altos, em vez de atingir o ponto mínimo. O mais importante é que a inclinação (derivada) fornece o passo e a direção do passo. Portanto, não se preocupe.
- Atualização da equação é esta. Diz que existe uma função de custo (leva em consideração o peso e a tendência). Tome derivada da função de custo de acordo com o peso e o viés. Em seguida, multiplique-o pela taxa de aprendizado α. Atualize o peso. (Para explicar, ignoro o viés, mas todas essas etapas serão aplicadas ao viés)

- Agora, tenho certeza de que você está perguntando qual é a taxa de aprendizado que nunca mencionei. É um termo muito simples que determina a taxa de aprendizado. No entanto, existe uma troca entre aprender rápido e nunca aprender. Por exemplo, você está em Paris (custo atual) e deseja ir a Madrid (custo mínimo). Se a sua velocidade (taxa de aprendizado) é pequena, você pode ir a Madri muito lentamente e leva muito tempo. Por outro lado, se a sua velocidade (taxa de aprendizado) for grande, você pode ir muito rápido, mas talvez faça um acidente e nunca vá a Madri. Portanto, precisamos escolher sabiamente a nossa velocidade (taxa de aprendizado).
- A taxa de aprendizado também é chamada de hiper parâmetro que precisa ser escolhido e ajustado. Vou explicar mais detalhadamente em rede neural artificial com outros hiper parâmetros. Por enquanto, basta dizer que a taxa de aprendizado é 1 no exemplo anterior.
- Acho que agora você entende a lógica por trás da propagação direta (de pesos e viés ao custo) e propagação reversa (do custo aos pesos e viés para atualizá-los). Além disso, você aprende descida gradiente. Antes de implementar o código, você precisa aprender mais uma coisa: como derivamos a função de custo de acordo com pesos e viés. Não está relacionado com python ou codificação. É pura matemática. Existem duas opções: a primeira é pesquisar no Google como derivar a função de perda de log e a segunda é pesquisar no Google o que é derivada da função de perda de log .Escolho a segunda porque não consigo explicar matemática de forma escrita, só falando mesmo..


Até este ponto aprendemos:
- Inicializando parâmetros (implementados)
- Localizando custo com propagação direta e função de custo (implementado)
- Atualização (aprendizado) de parâmetros (peso e viés). Agora vamos implementá-lo.

- Cansativo não é?... é a vida de um cientista de dados rsrs..Até este ponto, aprendemos nossos parâmetros. Isso significa que ajustamos os dados.
- Para prever, temos parâmetros. Portanto, vamos prever.
- Na etapa de previsão, temos x_test como entrada e, enquanto a usamos, fazemos previsões futuras.

- Fizemos nossa previsão
- Agora vamos colocar tudo junto.



- Aprendemos lógica por trás da rede neural simples (regressão logística) e como implementá-la.
- Agora que aprendemos a lógica, podemos usar a biblioteca sklearn, que é mais fácil do que implementar todas as etapas manualmente para regressão logística.
Regressão Logística com Sklearn
- Na biblioteca sklearn, existe um método de regressão logística que facilita a implementação da regressão logística.
- Eu não vou explicar cada parâmetro de regressão logística no sklear, mas se você quiser, pode ler a partir daqui: http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html
- As precisões são diferentes daquilo que encontramos. Como o método de regressão logística usa muitos recursos diferentes que não usamos, como diferentes parâmetros de otimização ou regularização.
- Vamos concluir a regressão logística e continuar com a rede neural artificial.

Resumo e respostas em mente:
O que fizemos nesta primeira parte:
- Inicialização dos parâmetros peso e viés
- Função de perda
- Função de custo
- Propagação para trás - retro-propagação (gradiente descendente)
- Previsão com parâmetros aprendidos peso e viés
- Regressão logística com sklearn
Se você tem alguma dúvida até este ponto, pergunte-me, porque nós iremos construir uma rede neural artificial em regressão logística.
DEVER DE CASA: Aqui é um bom lugar para parar e praticar. Sua tarefa é criar seu próprio método de regressão logística e classificar dois dígitos diferentes da linguagem de sinais.
Rede Neural Artificial (RNA) / Artificial Neural Network (ANN)
- É também chamado de rede neural profunda ou Deep Learning.
- O que é rede neural: é basicamente pegar a regressão logística e repeti-la pelo menos duas vezes.
- Na regressão logística, existem camadas de entrada e saída. No entanto, na rede neural, há pelo menos uma camada oculta entre a camada de entrada e saída.
- O que é profundo (Deep), para dizer "Deep" quantas camadas eu preciso ter: Quando faço essa pergunta ao meu professor, ele disse que "Deep" é um termo relativo; é claro que se refere à "profundidade" de uma rede, o que significa quantas camadas ocultas ela possui. "Qual a profundidade da sua piscina?" pode ter 12 pés ou dois pés; no entanto, ainda tem profundidade - tem a qualidade de "profundidade". Há 32 anos, se usava duas ou três camadas ocultas. Esse era o limite para o hardware especializado da época. Apenas alguns anos atrás, 20 camadas eram consideradas bastante profundas. Em outubro, Andrew Ng mencionou 152 camadas (uma das? ) as maiores redes comerciais que ele conhecia. Na semana passada, conversei com alguém de uma empresa grande e famosa que disse que estava usando "milhares". Portanto, prefiro ficar com "Qual a profundidade?"
- Por que é chamado de oculto: porque a camada oculta não vê entradas (conjunto de treinamento)
- Por exemplo, você tem uma camada oculta e uma de saída. Quando alguém lhe pergunta "ei, meu amigo, quantas camadas sua rede neural tem?" A resposta é "Eu tenho uma rede neural de 2 camadas". Porque enquanto a camada de entrada do número da camada de computação é ignorada.
- Vamos ver a rede neural de 2 camadas:

- Passo a passo, vamos aprender sobre esta imagem.
- Como você pode ver, há uma camada oculta entre as camadas de entrada e saída. E essa camada oculta tem 3 nós. O número de nós é um hiper parâmetro como a taxa de aprendizado. Portanto, veremos hiper parâmetros no final da rede neural artificial.
- As camadas de entrada e saída não mudam. Eles são iguais à regressão logística.
- Na imagem, há uma função *tanh* desconhecida para você. É uma função de ativação como a função sigmoide. A função de ativação do *Tanh* é melhor que o sigmoide para unidades ocultas, porque a média de sua saída é mais próxima de zero e, portanto, centraliza melhor os dados na próxima camada. Além disso, a função de ativação tanh aumenta a não linearidade que faz com que o nosso modelo aprenda melhor.
- Como você pode ver na cor roxa, existem duas partes. Ambas as partes são como regressão logística. A única diferença é a função de ativação, entradas e saídas.
- Na regressão logística: input => output
- Na rede neural de 2 camadas: entrada => camada oculta => saída. Você pode pensar que a camada oculta é saída da parte 1 e entrada da parte 2.
- Isso é tudo. Seguiremos o mesmo caminho, como a regressão logística para redes neurais de 2 camadas.
Rede Neural de 2 Camadas
- Tamanho das camadas e pesos dos parâmetros de inicialização e viés
- Propagação direta
- Função de perda e função de custo
- Propagação para trás( retro - propagação)
- Parâmetros de atualização
- Previsão com parâmetros aprendidos peso e viés
- Criação do modelo
Tamanho das camadas e pesos dos parâmetros de inicialização e viés
- Para x_train que possui 348 amostras

- Na regressão logística, inicializamos os pesos 0,01 e viés 0. Nesse momento, inicializamos os pesos aleatoriamente. Porque se inicializarmos os parâmetros zero, cada neurônio na primeira camada oculta executará a mesma compilação. Portanto, mesmo após múltiplas iterações de descida de gradiente, cada neurônio na camada estará computando as mesmas coisas que outros neurônios. Portanto, inicializamos aleatoriamente. Também os pesos iniciais serão pequenos. Se forem muito grandes inicialmente, isso fará com que as entradas do *tanh* sejam muito grandes, fazendo com que os gradientes sejam próximos de zero. O algoritmo de otimização será lento.
- A polarização pode ser zero inicialmente.

Propagação Direta
- A propagação direta é quase a mesma da regressão logística.
- A única diferença é que usamos a função tanh e fazemos todo o processo duas vezes.
- Também numpy tem a função tanh. Portanto, não precisamos implementá-lo.

Função de Custo e Perda
- As funções de perda e custo são iguais à regressão logística
- Função de entropia cruzada


Propagação para trás / Retro - Propagação
- Como você sabe, propagação para trás significa derivada.

Parâmetros de Atualização
- A atualização de parâmetros também é igual à regressão logística.
- Na verdade, trabalhamos muito com regressão logística

Previsão com Parâmetros Aprendidos - Peso e Viés
- Vamos escrever o método de previsão semelhante à regressão logística.

Criação do Modelo
- Vamos juntar tudo




Até este ponto, criamos uma rede neural de duas camadas e aprendemos a implementar:
- Tamanho das camadas e pesos dos parâmetros de inicialização e viés
- Propagação direta
- Função de perda e função de custo
- Propagação para trás ( retro - propagação )
- Parâmetros de atualização
- Previsão com parâmetros aprendidos peso e viés
- Criação do Modelo
Agora vamos aprender como implementar a rede neural da camada L com keras.
Rede Neural de Camada - L
- O que acontece se o número de camadas ocultas aumentar: As camadas anteriores podem detectar recursos simples.
- Ao modelar a composição de recursos simples em camadas posteriores da rede neural, ele pode aprender funções cada vez mais complexas. Por exemplo, vamos olhar para o nosso sinal um.

- Por exemplo, a primeira camada oculta aprende arestas ou formas básicas como linha. Quando o número de camadas aumenta, as camadas começam a aprender coisas mais complexas, como formas convexas ou recursos característicos, como o indicador.
- Vamos criar o nosso modelo
- Existem alguns hiper parâmetros que precisamos escolher como taxa de aprendizado, número de iterações, número de camada oculta, número de unidades ocultas, tipo de funções de ativação.
- Esses hiper parâmetros podem ser escolhidos de forma intuitiva se você passar muito tempo no mundo do Deep Learning.
- No entanto, se você não gastar muito tempo, a melhor maneira é pesquisar no Google, mas isso não é necessário. Você precisa tentar hiper parâmetros para encontrar o melhor.
- Neste tutorial, nosso modelo terá 2 camadas ocultas com 8 e 4 nós, respectivamente. Porque quando o número de camadas e nós ocultos aumenta, leva muito tempo.
- Como função de ativação, usaremos relu(primeira camada oculta), relu(segunda camada oculta) e sigmoide (camada de saída), respectivamente.
- O número de iterações será 100.
- Nosso caminho é o mesmo com as partes anteriores. No entanto, à medida que você aprende a lógica por trás do Deep Learning, podemos facilitar nosso trabalho e usar a biblioteca keras para redes neurais mais profundas.
- Primeiro vamos remodelar nosso x_train, x_test, y_train e y_test.

Implementação com Biblioteca Keras
Vamos analisar alguns parâmetros da biblioteca keras:
- unidades: dimensões de saída do nó
- kernel_initializer: para inicializar pesos
- ativação: função de ativação, usamos relu
- input_dim: dimensão de entrada que é o número de pixels em nossas imagens (4096 px)
- otimizador: usamos adam optimizer
- Adam é um dos algoritmos de otimização mais eficazes para o treinamento de redes neurais.
- Algumas vantagens de Adam é que os requisitos de memória são relativamente baixos e geralmente funcionam bem mesmo com pouco ajuste de hiper parâmetros
- perda: A função de custo é a mesma. A propósito, o nome da função de custo é a função de custo de entropia cruzada usada pelas partes anteriores.

- métricas: é precisão.
- cross_val_score: use validação cruzada. Se você não conhece a validação cruzada, consulte-a no meu tutorial de aprendizado de máquina.
- épocas: número de iterações

O resultado de saída é muito grande, são 100 passos, por isso vou colocar o print somente dos últimos 6 passos e do resultado final, caso queira ver todos os passos, podem acessar ao Kernel no meu Kaggle, que terá o link no fim do artigo
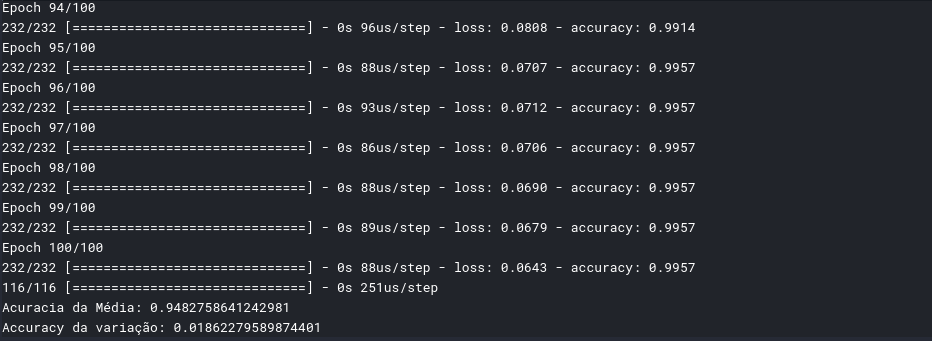
Conclusão
- Se você vir minha ortografia errada (pode ser demais), ignore-as :)
- Este tutorial é superficial, se você quiser obter mais detalhes sobre alguns conceitos, pode comentar.
- Agora espero que você entenda e aprenda o que é Deep Learning. No entanto, não escrevemos códigos longos para cada vez para criar um modelo de aprendizado profundo. Portanto, há um quadro de aprendizado profundo para criar modelos de aprendizado profundo de maneira rápida e fácil.
Notebook do meu Kaggle com o código completo e data sets : https://www.kaggle.com/nelsonpereira/tutorial-de-deep-learning
Script Python no meu Git:https://github.com/NelsonZyon/Data-Science/blob/master/Tutorial_deep_learning.py
Espero que tenham gostado e não esqueçam de comentar no artigo, vossa opinião é muito importante.
Abraços e bons estudos!!
Espero que tenham gostado e não esqueçam de comentar no artigo, vossa opinião é muito importante.
Abraços e bons estudos!!
Referências
- Artificial Neural Network: https://www.kaggle.com/kanncaa1/pytorch-tutorial-for-deep-learning-lovers
- Convolutional Neural Network: https://www.kaggle.com/kanncaa1/pytorch-tutorial-for-deep-learning-lovers
- Recurrent Neural Network: https://www.kaggle.com/kanncaa1/recurrent-neural-network-with-pytorch
- Data Science: https://www.kaggle.com/kanncaa1/data-sciencetutorial-for-beginners
- Machine learning: https://www.kaggle.com/kanncaa1/machine-learning-tutorial-for-beginners



Comentários
Postar um comentário